Best practices
This section provides best practices and general guidelines to help you design, optimize, and maintain efficient, secure, and reliable automations in Quickwork.
When to use webhooks over API
Quickwork offers powerful integration capabilities through both webhooks and APIs, supporting multiple data formats such as JSON, XML, and Text input. Here's a breakdown of the best practices for utilizing these connections effectively.
Webhooks
Webhooks in Quickwork can use universal connectors like HTTP and WebSockets to generate endpoints. These endpoints can receive traffic and payloads from any source system, including third-party or custom-designed software applications. Webhooks follow a "fire and forget" mechanism, meaning they do not wait for a reply from the Journey. Quickwork acknowledges each request sent to the webhook with a 200 status code and a message body stating "OK" This system supports payloads up to 10 MB, or even larger if octet streaming is used. Although webhooks also have a 90-second timeout, they typically respond within 100 milliseconds as no response is expected from the API.
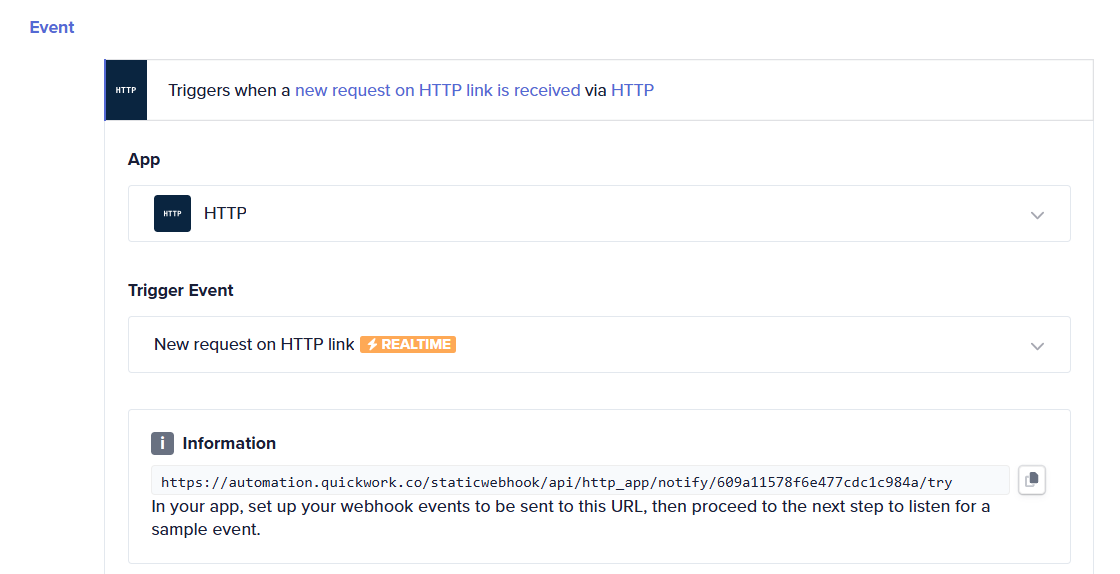
The example below shows a webhook created within a Journey. It generates a unique URL that can be consumed by the client.
API management
API management in Quickwork works in conjunction with Callable Journeys, allowing you to convert a function into an API. This setup supports synchronous request-reply patterns, providing a response from the Journey within 90 seconds. If no response is received, the request timed out, returning a 504 error. API management requires an authentication mechanism such as API Key, OAuth, or Mutual TLS; without this, the API cannot be exposed. Each API request is limited to a 1MB payload. Exceeding this limit results in an "entity too large" error, necessitating a smaller request body. API management also offers rate-limiting, quota management, and IP whitelisting to protect your API on the internet, features not available in webhook-based systems.
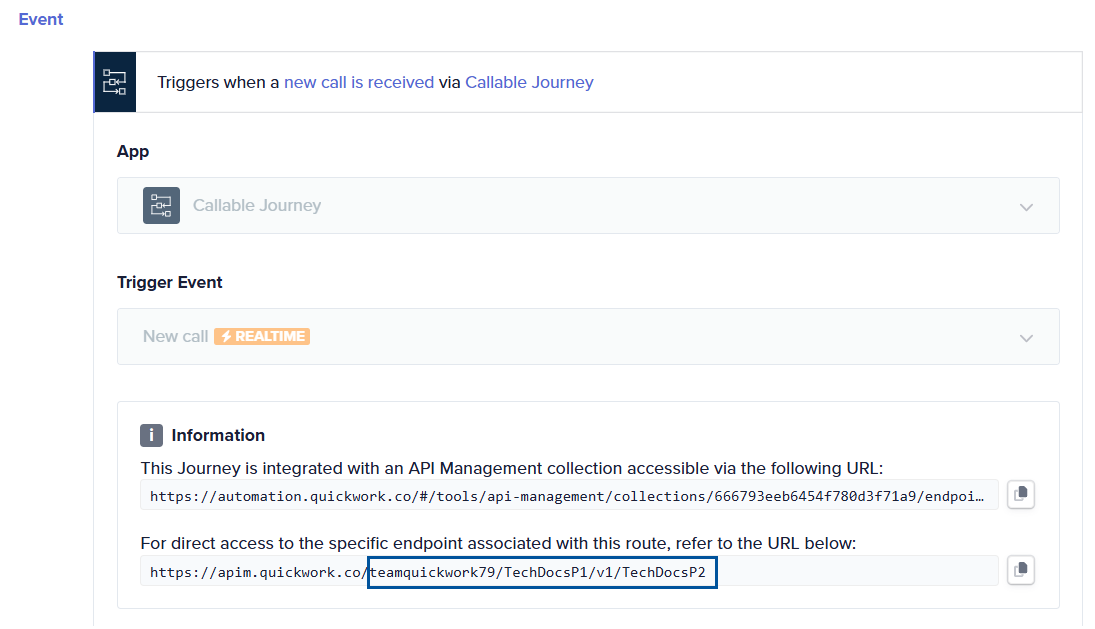
The example below indicates an API connected/linked to a Callable Journey with an route endpoint with authentication mechanism associated.
Choosing between webhooks and APIs
The choice between webhooks and APIs depends on the specific requirements of your integration. Use webhooks for scenarios where real-time data delivery is essential and immediate acknowledgement is sufficient. Webhooks are ideal when no response is expected from the Journey, allowing for quick processing. In contrast, APIs are suitable when synchronous responses are needed, and robust security measures are required. APIs should be used with the preferred authentication mechanism to ensure secure and reliable data exchange.
Choosing the right type of triggers depending on the use case and complexity
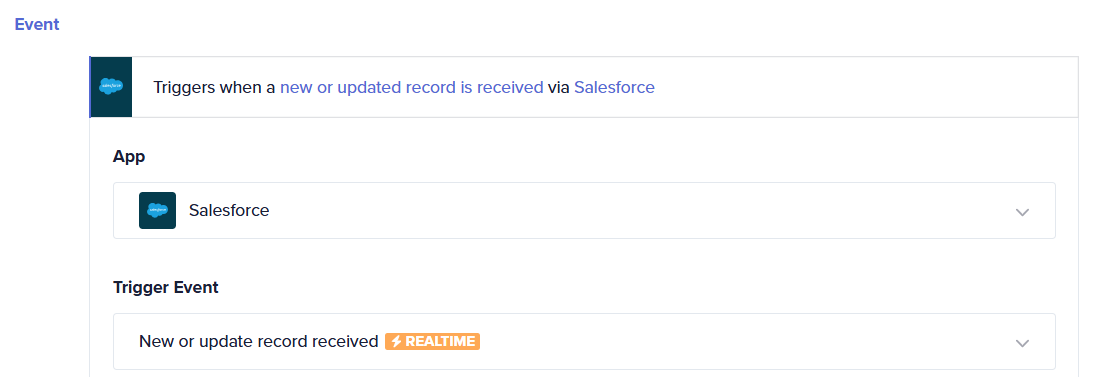
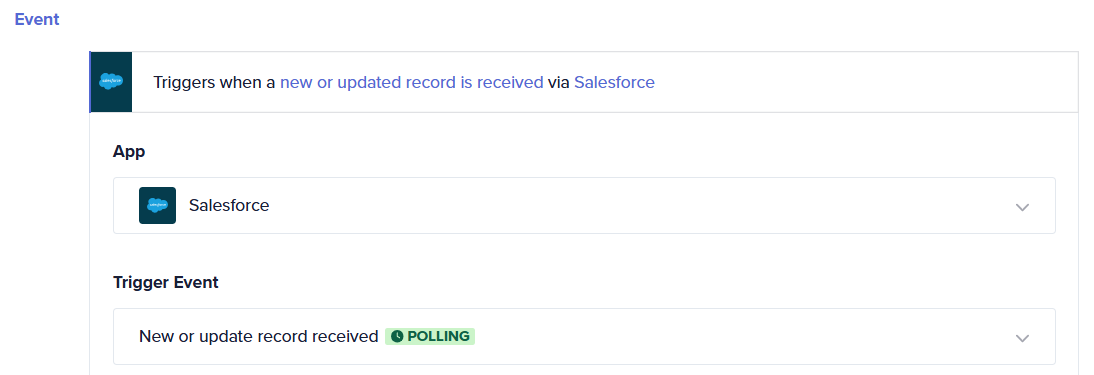
Quickwork supports various types of triggers, including Real-time (Webhooks, APIs), Polling, Scheduler, Change Data Capture, and Human Manual Interrupts. In some cases, Quickwork offers multiple options for the same trigger type, as illustrated below with an example from Salesforce.
Types of triggers
Real-time triggers: Real-time triggers, such as HTTP event-driven triggers, execute actions immediately after a change occurs. This approach is highly efficient and ensures timely operations. However, real-time triggers often require additional setup in the client's underlying system. For instance, in Salesforce, modifications and additions of APEX classes might be necessary. Real-time triggers process events individually, which may not support batch changes. Additionally, since most real-time triggers are powered by webhooks, there is a risk of request loss if the webhook does not receive the request. This could be due to network issues such as firewall rules, network blocking systems, or connectivity problems. While many third-party systems, like Salesforce, retry undelivered requests, some may simply report an error without retrying.
The example below is that of a real-time HTTP event-driven trigger.
Polling triggers: Polling triggers check for changes at regular intervals, such as every minute. While this method introduces a delay compared to real-time triggers, it ensures continuity and reliability. Polling triggers maintain state and deduplication entries, allowing the system to resume from the last polled point after downtime, ensuring no events are missed. The deduplication system ensures no single event is processed twice by following idempotence rules.
The example below is that of a polling trigger that checks for changes every 1 minute.
Comparison and use cases
Both real-time and polling triggers perform the same operation but with different efficiencies and requirements. Real-time triggers are superior for immediate execution but require more complex setups and are susceptible to network issues. Polling triggers, though slightly delayed, offer robustness and reliability by maintaining state and ensuring no event is lost or duplicated.
Choosing the right trigger
Selecting the appropriate trigger type depends on your use case and system requirements. Use real-time triggers when immediate response and efficiency are critical, and you can manage the additional setup and potential network issues. Opt for polling triggers when reliability, ease of setup, and state maintenance are priorities, even if it means a slight delay in processing.
Payload size limits and performance optimisations with batching
Each transaction executed in Quickwork runs in its own dedicated container, ensuring complete isolation, security, and higher throughput. This containerized approach guarantees that no two transactions can interact or interfere with each other under any circumstances.
Resource allocation and limits
To maintain this level of isolation, each transaction is allocated a fixed set of resources, specifically CPU and memory. The CPU allocation determines the processing speed of the transaction, while the memory allocation is critical to avoid errors. Exceeding the predefined memory limit results in an "Out Of Memory" (OOMKilled) error. For example, while running a custom SQL in MySQL.
By default, Quickwork allocates 256 MB of memory per transaction, which is typically sufficient for most use cases. However, when handling extremely large payloads, spanning thousands of records, this limit may be exceeded, resulting in an OOMKilled error.
Best practices to avoid OOMKilled errors
- Batch processing: Extract data from your source system in batches rather than trying to retrieve all information at once. This approach reduces the memory load on each transaction.
- Callable Journeys: Use Callable Journeys to divide the process into smaller tasks. By breaking down large payloads into smaller chunks, you can process data more efficiently and avoid memory overflows.
Quickwork can also assist in increasing the memory limit for specific workflows if necessary. However, adopting these best practices ensures smoother and more efficient processing without requiring additional memory resources. By following these guidelines, you can effectively manage transactions in Quickwork, ensuring reliability and performance while avoiding common errors related to resource limits.
Enable data masking and/or disable data storage
When integrating core systems as part of the Journey orchestration process, handling confidential data securely is crucial. Quickwork ensures data security by adhering to various security standards and encryption mechanisms. However, in certain cases, it might be necessary to either store partial data or not store any data at all. Quickwork provides mechanisms to achieve this through data masking, trasaction tables (custom history tables), and options to disable data storage entirely at the Journey level.
Data masking
Data masking is a step-level feature that ensures data is stored only until the transaction is completed. It guarantees that the data is never visible to the end-user, even if it is pending. Once a transaction is marked as successful or failed, all step data is instantly deleted from all storages, including backups, ensuring utmost confidentiality.
The example below is of data masking enabled on a specific step.
Trasaction tables (Custom history tables)
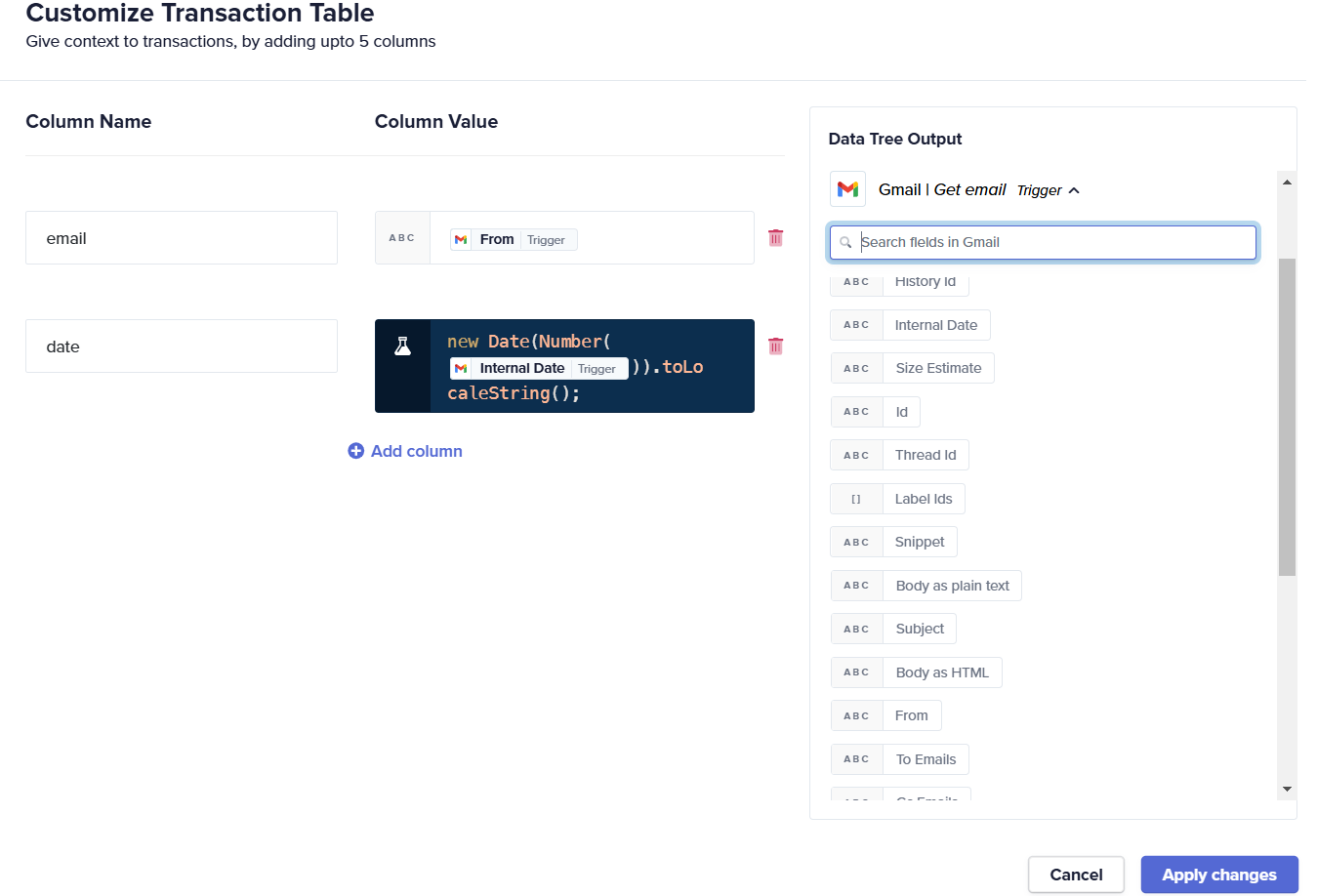
Custom history tables, or Edit Tables, are a Journey-level feature that allows you to selectively extract and display data from the workflow, ensuring that only necessary information is available for debugging purposes. This approach prevents the exposure of all input and output data across the steps in your Journey.
The example below shows Edit Table where specific fields are displayed using a combination of data pills and formulas to dynamically populate values during Journey execution.
The example below shows selective extract and display of data from the Journey.
Disabling data storage
The Step data storage is a Journey-level feature that allows you to completely disable data storage across the entire Journey without needing to enable masking at individual steps. This not only enhances performance but also ensures that no data is stored in Quickwork.
The example below is of disabling step data storage on a specific Journey.
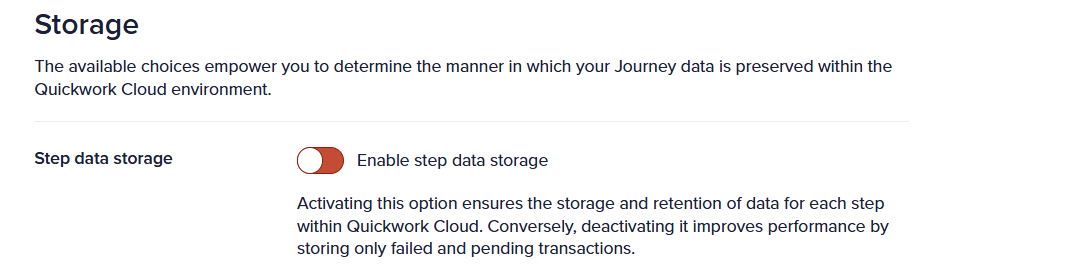
The error message when attempting to access history data after disabling storage.
Streaming data to external systems
Customers have the option to stream data to their preferred logging or SIEM (Security Information and Event Management) systems. This ensures that while Quickwork does not store any data, customers can continue to store all kinds of data in their preferred historical data storage systems, such as S3, Datadog, or EFK. This practice is highly recommended to maintain data security and accessibility. By utilizing these features, you can handle confidential data securely in Quickwork, ensuring both compliance and efficiency in your workflow orchestration processes.
Make use of provisioned concurrency for fixed throughput and order gaurantees
Quickwork offers a mechanism to allocate a fixed amount of concurrency to specific workflows, ensuring consistent throughput even in heavily populated accounts. This feature allows you to reserve resources for critical workloads where delays are unacceptable, maintaining reliable performance under varying loads.
Provisioned concurrency
Provisioned concurrency guarantees that a certain portion of your account’s resources is dedicated to specific workflows. This ensures that, regardless of the overall transaction volume, critical workflows receive the necessary resources for timely execution. The example is of provisioned concurrency enabled with order guarantee.

Without this feature, transactions are placed in a shared pool within your account. High-volume workflows can monopolize bandwidth, leading to delays in other processes. Provisioned concurrency mitigates this by reserving dedicated resources for critical tasks.
Additional features
Provisioned concurrency includes nested features such as order guarantee and advanced telemetry, enhancing its utility.
- Order guarantee: This feature ensures that transactions are processed sequentially, which is crucial for workflows where the order of operations matters, such as financial transactions, account statements, and reconciliations. Quickwork guarantees that messages are processed in the order they are received.
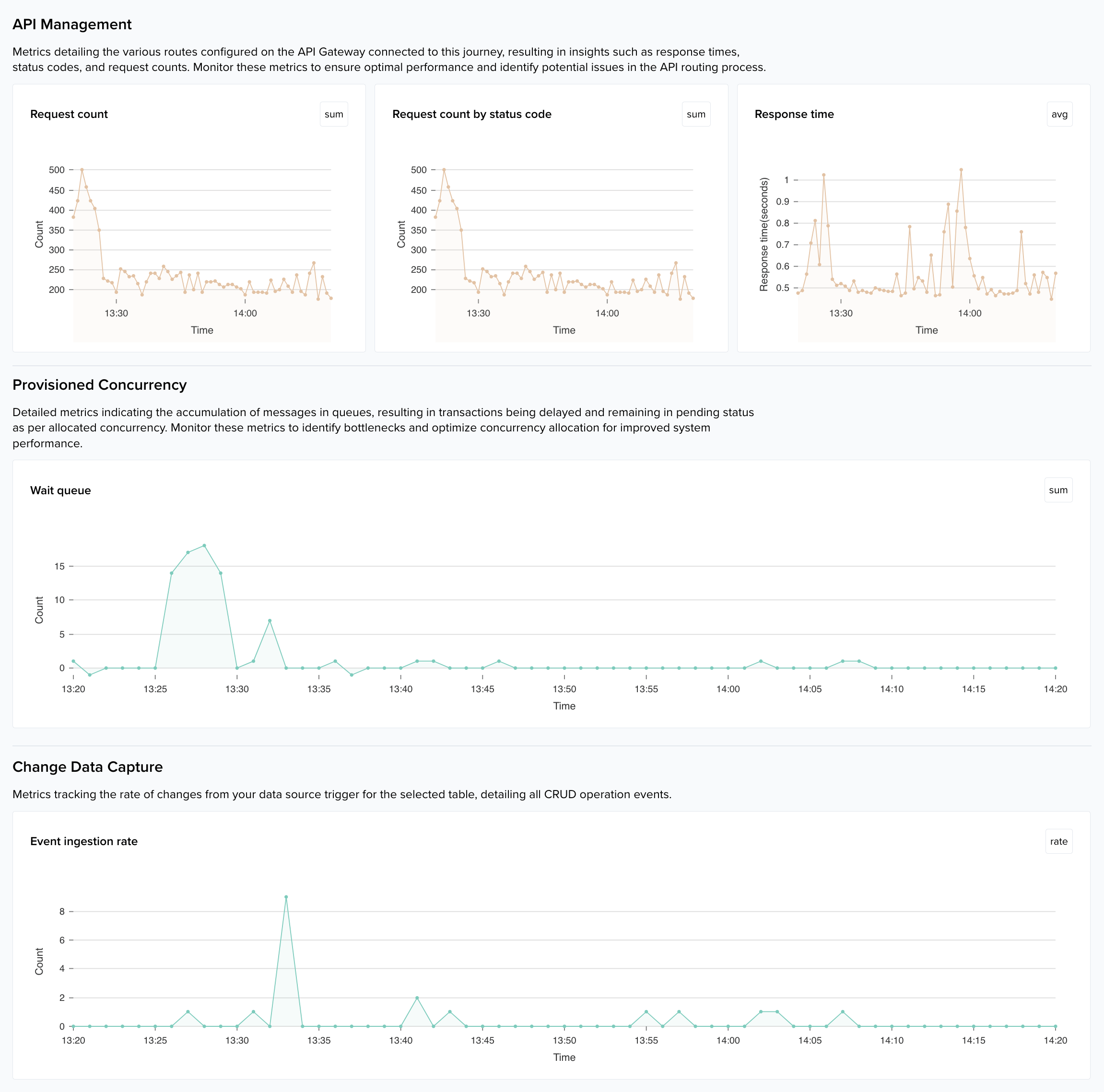
- Telemetry: Quickwork provides advanced telemetry for monitoring workflow performance. Depending on the workflow, you might have API Management, Change Data Capture (CDC), or Wait queue monitoring dedicated to your Journey. The Monitoring tab appears automatically when these features are enabled.
The example below illustrates the monitoring view for a Journey managed through API Management, Wait queue, CDC.
Use cases
Enable provisioned concurrency when working with critical workloads that require timely execution and strict order of operations. This feature is particularly beneficial in scenarios where delays or out-of-order processing could have significant negative impacts. By leveraging provisioned concurrency and its associated features, you can ensure that your most critical workflows perform reliably and efficiently, even under high load conditions.
API mananagement on front-end projects
Quickwork allows you to publish APIs to the internet with a preferred authentication mechanism. However, it is crucial to avoid using API key-based authentication in purely front-end projects. Doing so can expose your API keys to any user with basic debugging tools, compromising your tokens in a public environment.
Avoid API key-based authentication in front-end projects: API keys are easily exposed in front-end code. When used in front-end projects, these keys can be accessed by anyone using simple debugging tools, leading to potential security breaches. To prevent this, do not use API Key-based authentication for front-end applications.
Use JWT with OAuth for front-end projects: For front-end projects, it is recommended to use JSON Web Tokens (JWT) with OAuth-based authentication. This approach provides a more secure method for handling authentication, reducing the risk of exposing sensitive tokens.
Utilize an API gateway as a proxy: Another effective strategy is to use your preferred API gateway as a proxy for your APIs. This adds an additional layer of security, protecting your API keys and ensuring secure communication between your front-end and back-end services. By adhering to these best practices, you can securely manage API authentication in Quickwork, safeguarding your tokens and maintaining the integrity of your applications.
Avoid recursive when using trigger and action of the same app
A common mistake users make is setting up a Journey where the trigger and action belong to the same app and same entity. This can lead to recursion, which consumes excessive API calls and may incur additional costs from both Quickwork and third-party services, such as Salesforce.
Understanding recursion in triggers and actions
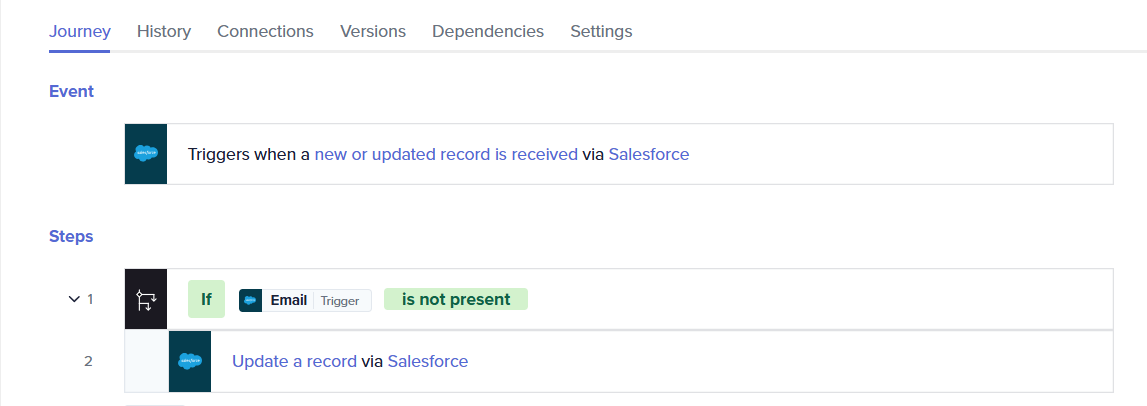
For example, consider a Salesforce setup with the accounts entity. If you configure a trigger to initiate automation every time there is a new entry in the Accounts object, and then have an action that updates the same Accounts object, this will retrigger the automation, causing a loop. This recursive loop wastes a significant number of API calls.
The example below is of updating the same entity in the same app as the listener, causing recursion.
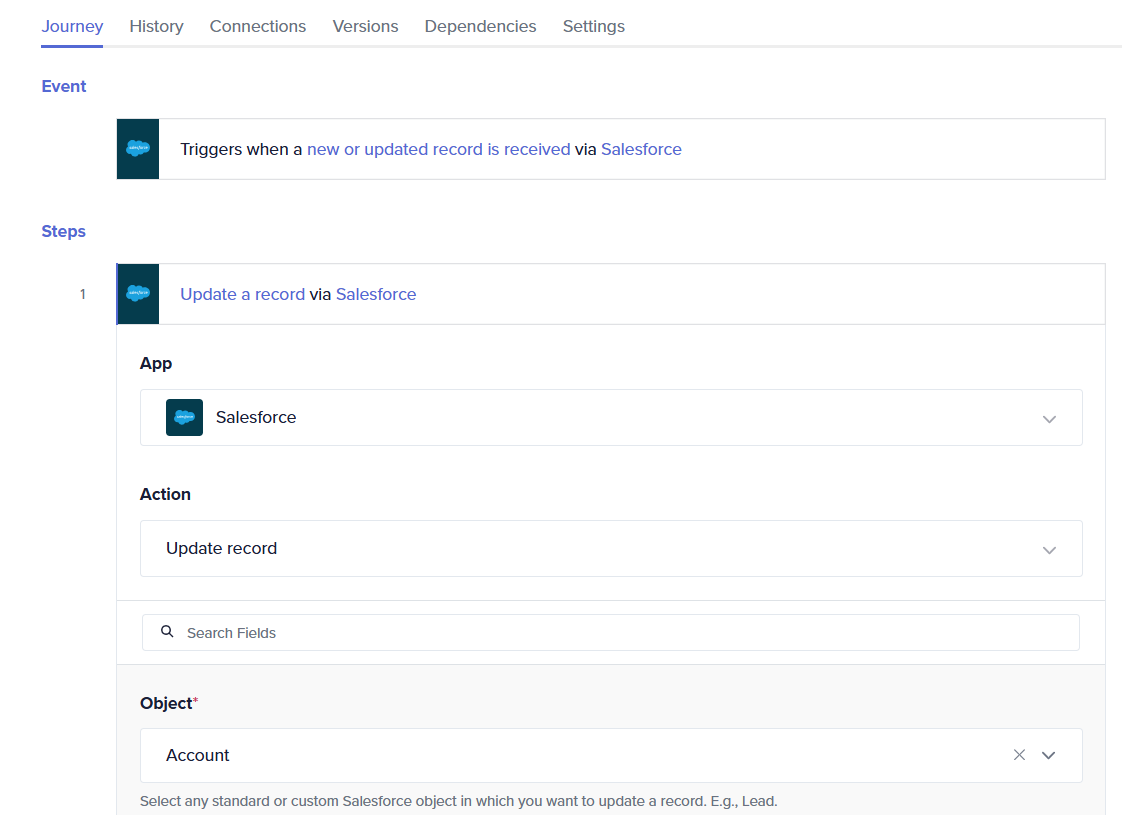
While Quickwork does provide anomaly detection to identify potential recursion issues, it can be challenging to discern whether it is a genuine implementation requirement or an unintentional recursion. Therefore, it is crucial for the user to implement a stop condition to prevent recursion.
Implementing stop Journey conditions
To avoid recursion, add a validation condition that stops the loop from occurring. This condition should be designed to recognize when the action should not retrigger the automation.
To avoid recursion, add a validation condition that stops the loop from occurring. This condition should be designed to recognize when the action should not retrigger the automation.
The example below is of adding a validation condition to prevent recursion.
Best practices
- Be cautious: Always be extra cautious when setting up triggers and actions within the same app and targeting the same entity.
- Implement stop conditions: Ensure to set up appropriate stop conditions to prevent unintentional recursion and excessive API call usage.
- Monitor for anomalies: Utilize Quickwork's anomaly detection features to monitor and identify potential issues early. By following these best practices, you can effectively prevent recursion in your workflows, ensuring efficient and cost-effective use of Quickwork iPaaS and third-party services.
Developing reusable components
When managing a large number of Journeys, you might encounter repetitive actions across various workflows. Placing these repetitive actions in individual workflows can be problematic, as any changes require you to update each workflow separately. To simplify this process and ensure consistency, it is highly recommended to use Callable Journeys.
Benefits of Callable Journeys
Callable Journeys allow you to convert steps into a function-style Journey that can be invoked from an API, other Journeys, and AI databases. This modular approach provides several advantages:
- Centralized updates: Changes made in a Callable Journey are automatically applied wherever it is called, saving time and reducing the risk of errors.
- Efficiency: Reusing common steps across multiple workflows enhances efficiency and maintainability.
- Flexibility: Callable Journeys can be called asynchronously or synchronously, depending on whether you need a response to proceed.
Usage scenarios
- Asynchronous calls: Use asynchronous calls when speed is crucial and you do not need an immediate response.
- Synchronous calls: Use synchronous calls when you need a response to continue with the workflow. Examples:
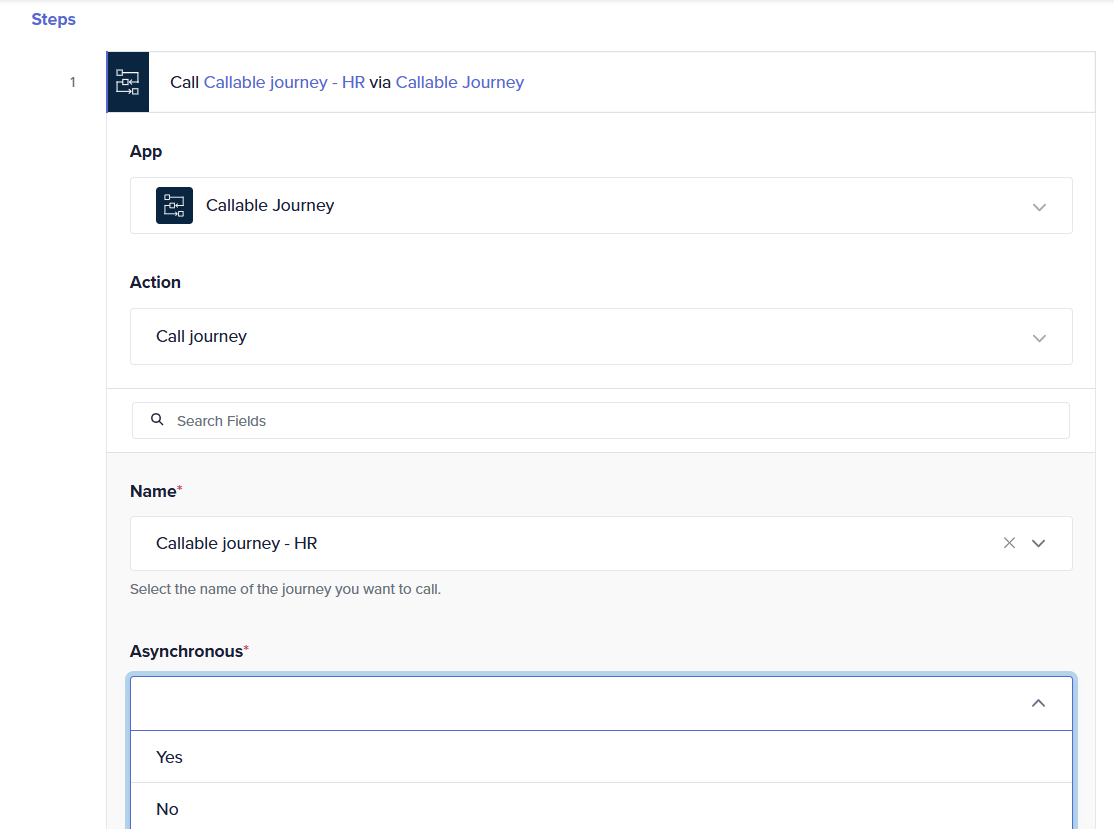
Calling a Journey from an API endpoint via API management
Dedicated connectors Vs universal connectors
Quickwork offers a wide range of universal connectors such as HTTP, SMTP, SFTP, SSH, and more. These connectors are termed "universal" because they can call any individual custom endpoint without requiring a specifically designed connector for that endpoint.
When to use universal connectors
Universal connectors provide significant flexibility and are ideal for straightforward integrations where custom endpoints need to be called without complex requirements. However, there are scenarios where developing a private connector may be more advantageous.
Criteria for using private connectors
Consider moving to a private connector if the following conditions are met:
- Multiple endpoints: When you have multiple endpoints pointing to the same service, managing them through a private connector can streamline operations.
- Complex authentication: If your integration involves complex authentication mechanisms, such as OAuth, a private connector can handle these securely and efficiently.
- Encryption/decryption needs: When payloads require encryption or decryption, a private connector ensures that these processes are managed correctly.
- Cross customer and cross accounts usage: For use cases that span across different customers or accounts, a private connector offers better scalability and management.
- Common 3rd party services: If you are integrating with a common third-party service that is generally accessible, a private connector can provide optimized and specialized functionalities.
- Telemetry and monitoring: Enhanced telemetry and monitoring capabilities are often necessary for critical integrations, which a private connector can offer.
- Dependency on libraries: When the integration depends on specific libraries before making the call, a private connector can incorporate these dependencies effectively.
Recommendation
If even a subset of these criteria are met, it is advisable to create a dedicated private or public connector. This ensures that your integrations are robust, secure, and maintainable, providing better performance and management capabilities. By carefully evaluating your integration needs and choosing the appropriate connector type, you can leverage Quickwork iPaaS to its fullest potential, ensuring efficient and secure workflow management.
Webhook authentication
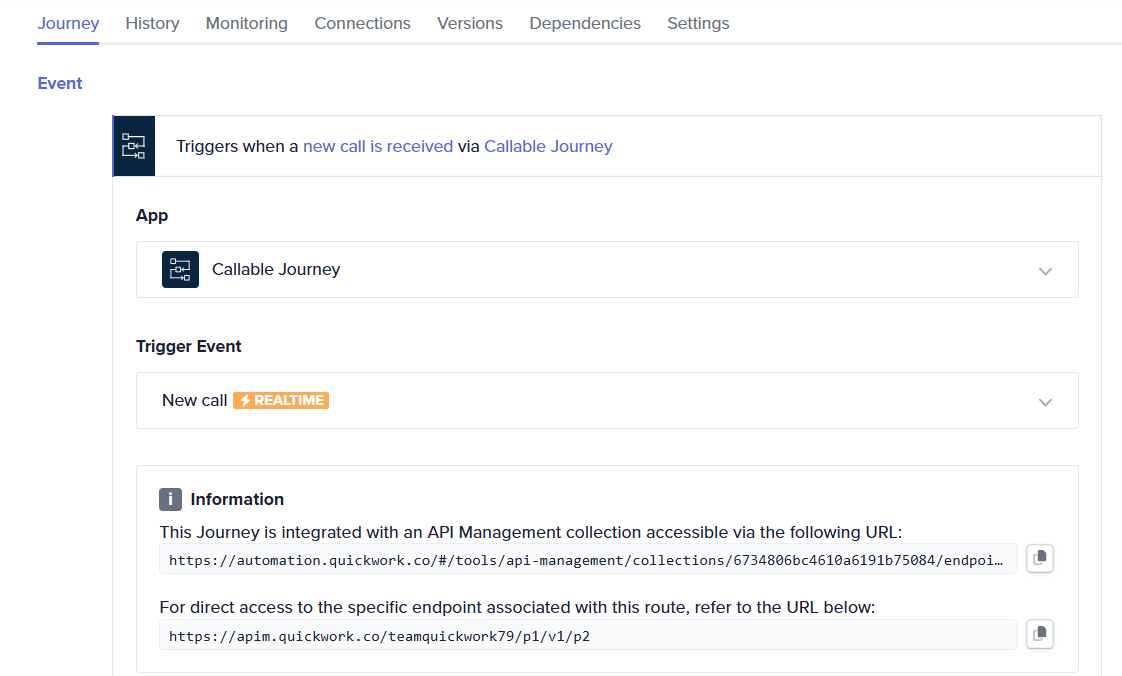
Webhooks are designed to be triggered without authentication from third-party services that invoke an operation on Quickwork. However, it is a good practice to implement authentication on top of the webhook system by adding steps to the Journey that can be used for validation purposes. If you require a fully authenticated endpoint, it is best to use API Management with async invocation and one of the supported authentication mechanisms.
Option 1: Static API key validation
Use a regular query parameter field with a fixed static API key stored in Constants. Before executing any operation or step in your Journey, add a validation step to check whether the expected query parameter or header has been passed. If the key does not match, use a Stop Journey step to reject the request.
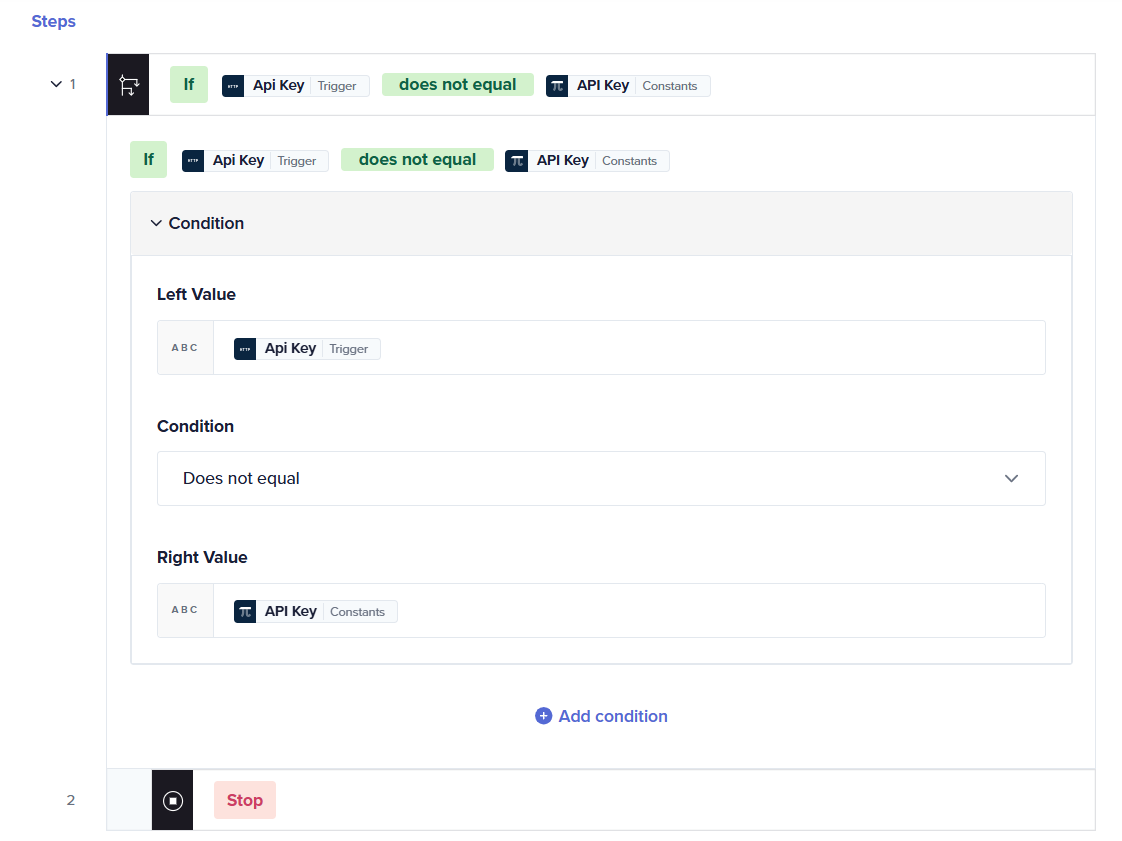
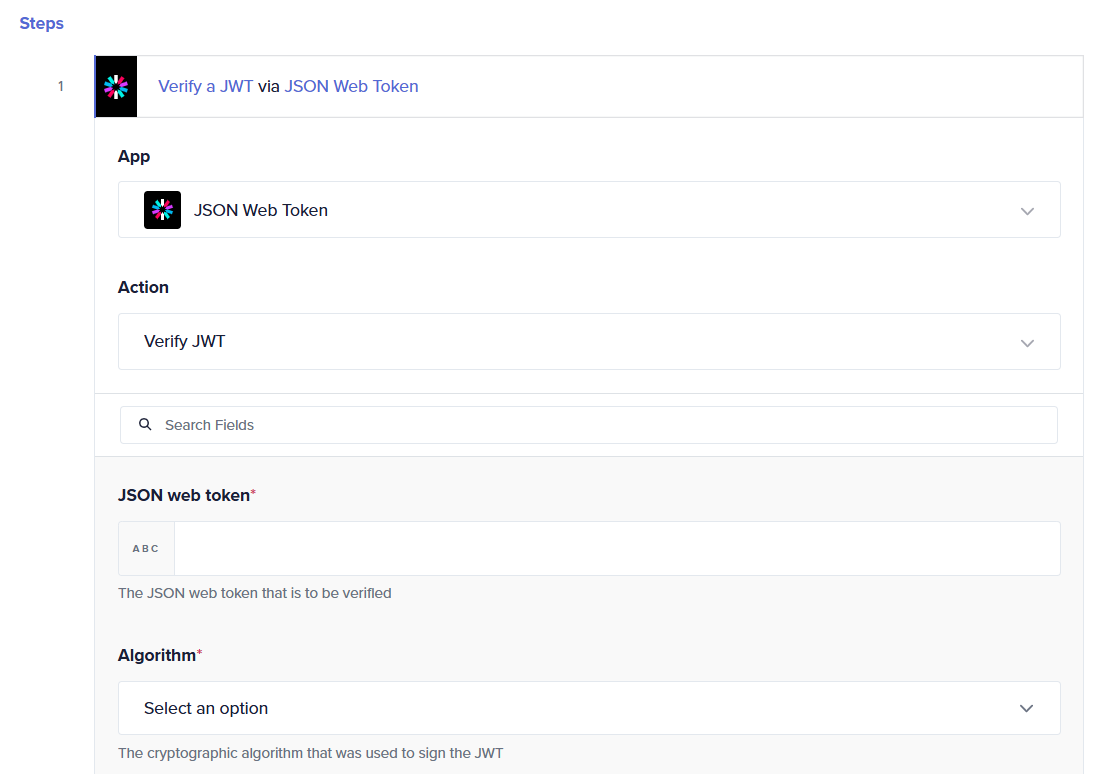
Option 2: JWT-based validation
Use the JWT connector to validate a JSON Web Token using either a secret key-based approach or a JWKS endpoint. The client should send the HTTP request with the JWT in the header, and the Journey should perform the validation before proceeding with any further steps. This approach is suitable when you need a more robust, standards-based authentication mechanism without moving to full API Management.